Initialisation de la chaine éditoriale
Dans le répertoire, _data on trouve 6 fichiers JupyterNoteBook (extension ipynb) :
- 0-clean-project.ipynb
- 1-build-tropy-schema
- 2-export-tropy-to-markdown.ipynb
- 3-export-tropy-csv.ipynb
- 4-split-csv.ipynb
- 5-generate-doi.ipynb
Ces fichiers contiennent des scripts permettant de configurer et synchroniser les données de votre corpus avec le serveur gitlab.
📌 Nettoyage du projet
Le premier script 0-clean-project.ipynb permet la suppression de toutes les données ayant servi à la publication de l'exemple initial (fiches, photos, ...). - Cliquez sur 0-clean-project.ipynb pour ouvrir le fichier
En haut de l'écran cliquez sur Run All  pour excuter le script. Il vous est demandé de choisir l'environnement python, choisissez anaconda si vous en avez plusieurs :
pour excuter le script. Il vous est demandé de choisir l'environnement python, choisissez anaconda si vous en avez plusieurs : 
A la fin du fichier, un résumé des actions réalisées est affiché
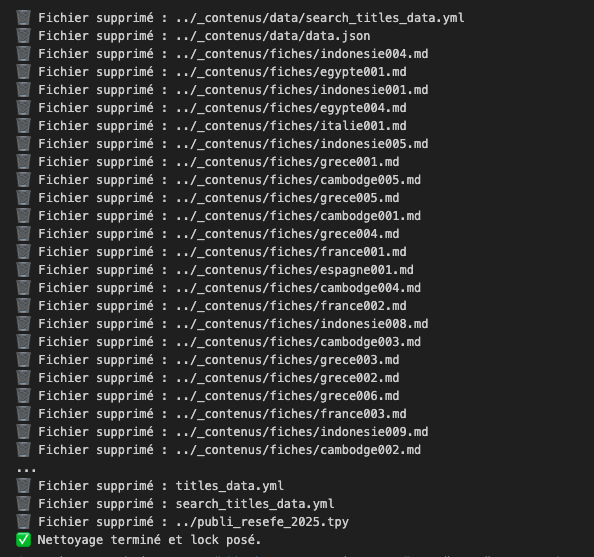
⚠️ Un fichier cleanup.lock est généré automatiquement et previent une suppression intempestive : si vous souhaitez supprimer à nouveau toutes les données vous devez préalablement supprimer ce fichier
📌 Configuration des métadonnées associées à votre corpus
La première étape pour un projet vierge consiste à définir les champs nécessaires à la description de votre corpus.
La première étape consiste à nommer votre projet :

⚠️ Le nom ne doit pas contenir de caractères spéciaux ou d'espaces.
Les fiches objet doivent a minima avoir un titre, idéalement un auteur, une description, et éventuellement une référence bibliographique issue de Zotero. On renseigne également un identifiant de groupe qui permet d'appeler les fiche objet à partir du texte. ⚠️ Cet identifiant doit impérativement commencer par une lettre (ex id_... )
Le premier script 1-build-tropy-schema , propose donc des champs par défaut (alignés sur le dublincore) qu'il ne faut pas modifier :
- Identifier
- Title
- Creator
- Description
- BibliographicCitation
- Groupe
Le champ Groupe permet de regrouper des notices sous un même label ce qui permettra de créer des ensembles liés à des parties de texte, de chapitre, ...
Vous avez également la possibiblité d'ajouter des champs spécifiques dédiés à votre projet. Dans l'exemple initial on avait :
- Source
- Typologie
- Dates
- Thème
- Pays
- Région
- Ville
- Site
- Couverture
- DOI
Vous pouvez modifier directement ces métadonnées dans le fichier 1-build-tropy-schema.ipynb :
data = [
"Source*",
"Typologie*",
"Dates*",
"Thème*",
"Pays*",
"Région*",
"Ville*",
"Site*",
"Couverture",
"DOI"]
Ajouter une * derrière les champs que l'on souhaite rendre interrogeable
Le champ couverture permettra de marquer les images que l'on souhaite afficher en priorité sur la page d'accueil en saisissant la valeur "home"
Une fois vos champs de métadonnées finalisés, vous pouvez générer les fichiers de configuration de Tropy :
En haut de l'écran cliquez sur Run All pour excuter le script. Il vous est demandé de choisir l'environnement python, choisissez anaconda si vous en avez plusieurs :
A la fin du fichier, un résumé des actions réalisées est affiché :

⚠️ Ne rien modifier dans l'espace 4 du fichier :
